Reliable Applications

Reliable Applications
Everybody has an intuitive idea of what it means for something to be reliable or unreliable. For software, typical expectations include:
- The application performs the function that the user expected.
- It can tolerate the user making mistakes or using the software in unexpected ways.
- Its performance is good enough for the required use case, under the expected load and data volume.
- The system prevents any unauthorized access and abuse.
We can understand reliability as meaning, roughly, “continuing to work correctly, even when things go wrong” as said by Martin Kleppman.
However, in this article, I'd like to look at reliability in a different light.
When I hear the word "reliability," the first thing that comes to mind is the computer networking course I took in college. We had the opportunity to learn about the Open Systems Interconnection (OSI) model in depth during this course. The OSI model describes seven layers that computer systems use to communicate over a network.
The Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) protocols are two important protocols of the Transport layer, also known as Layer 4 among these layers. When discussing the differences between TCP and UDP, it is commonly stated that TCP is reliable while UDP is unreliable.
What is the reliability?
I want to explain reliability from TCP and UDP perspective.
As you may know, request/response pairs are sent in a client-server architecture, and they use TCP to reduce and transport information in short packets of binary sequences of ones and zeros. So, in general, the smaller the size of these packets, the faster the response time.
TCP, unlike UDP, has extra loads at this point. Some of the causes of increased TCP packet size;
- Though since packet sequence is critical in TCP, the sequence number is kept in the header of each packet.
- Acknowledgment number information is also kept because it contains the sequence number of the data byte that the receiver expects to receive next from the sender. It's similar to a linked list data structure. As a result, each package keeps both its own sequence number and the sequence number of the next package, ensuring consistency.
TCP's header size varies between 20 and 60 bytes due to this and other overheads, whereas UDP's header size is only 8 bytes.
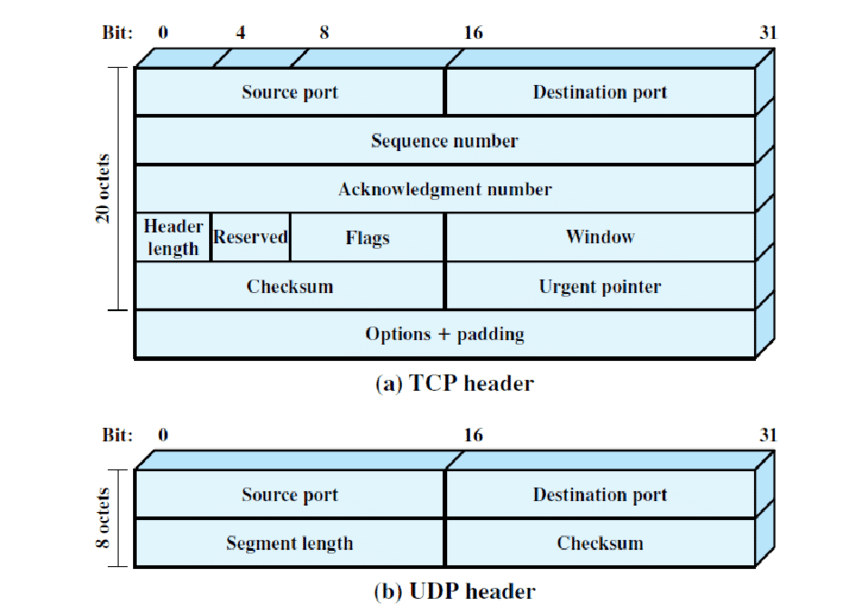
As a result, whether a packet is delivered properly to the receiver is critical for TCP but not for UDP. Because of this, TCP is a reliable communication protocol while UDP is not.
Why?
Since UDP isn't reliable, we might think that it shouldn't be used anywhere and that we should always use TCP instead. But that's not true; both can be used in the real world. But how can UDP, which is known for being unreliable, still be used in the real world? You can find the answer in the requirements.
UDP can be used in situations where performance is critical but packet loss is not. Think about multiplayer games.
Based on this, I can confidently state that adding more reliability to our application will impose additional responsibilities. For that job, perhaps the system does not need to be very reliable, as in the TCP-UDP comparison. Perhaps you're using TCP instead of UDP, which complicates matters and adds overhead to your application.
Conclusion
Based on these ideas, I wanted to briefly discuss reliability and the additional responsibilities it will enforce. Many applications, whether knowingly or unknowingly, suffer from over-engineering. As our experience grows and we gain a better understanding of the domain of the application we are working on, it may become easier to detect such situations.
Which of us didn't take the scenic route when we were interns?



